$$ \Huge \textbf{C中的数组} $$
$$ \boxed{ \overbrace{\textit{degaokaolization}}^{\small{去高考化}} \text{ Discussion Group | Topic 03C}} $$
回顾
在上面的内容中, 我们知道了如何对于若干个变量做各种各样的操作, 并且运用控制流使得他们做各种不同的事情. 此外, 我们还模块化了一些东西, 让我们可以轻松地调用.
了解了上面的内容之后, 我们就知道了#include "cs50.h"到底做了什么. 打开那份文件, 你会看到许许多多的函数声明, 每一个函数都实现了我们上次展示的功能. 但是你会发现, 有一些新奇的用法: 比如#define这些用#打头的指令, 以及奇怪的*. 不要担心. 我们在下一次就会遇到他们.
我们来看我们最开始的例子:
// Greeting.c
#include <stdio.h>
#include "cs50.h"
int main(){
string name = get_string("What's your name");
printf("Hello, %s", name);
}
其实我们第一次遇到的神秘指令无非就是一些函数调用. 在预处理器处理完这一群东西之后, 源文件就会变成这样:
...(Omitted)
string get_string(string prompt);
int printf(string format, ...);
...(Omitted)
int main(){
string name = get_string("What's your name");
printf("Hello, %s", name);
}
接下来, 编译的过程就会进行, 把它带到更低一层的汇编指令, 就像这样:
不过这个内容我们现在不必担心. 因为这是计算机专业在之后会了解的一个有趣的内容. 大多数时候, 不理解这个也不影响太多 - 毕竟这个更贴切与计算机自己理解东西的视角. 当编译器和高级语言没有被发明出来的时候, 人们就要用这样的方式操作电脑. 想想就非常的难以置信! 但是, 有些代码可能会被编译器经过一些很蠢的优化降低了性能, 那个时候, 可能也要像这样追求程序的效率了.
既然这个都已经摆在大家的面前了, 我们来实际看一下: 其中它也按照我们的要求用bl进行了函数的调用, 并且他们前面的add, ldr这一类的就是对于那些最小的单元们做的.
调试程序
在我们的程序变复杂之前, 我们最好要了解一下调试: 毕竟, 程序变得复杂之后, 我们就很难用脑力追踪程序运行一条之后, 里面的各个变化了. 所以, 我们自然有调试工具帮助我们!
第一层防线: 编译器
看下面的一段程序:
#include <stdio.h>
/*
Goal: Print a 3*3 square
*/
int main(){
for(int i=0; i<=3; i++){
for(int j=0; j<=3; j++){
printf("#")
}
}
return 0;
}
首先我们来编译一下, 发现编译器开始报错了 -

如果你配置好了编辑器的话, 把鼠标移到上面就会有这样的提示:
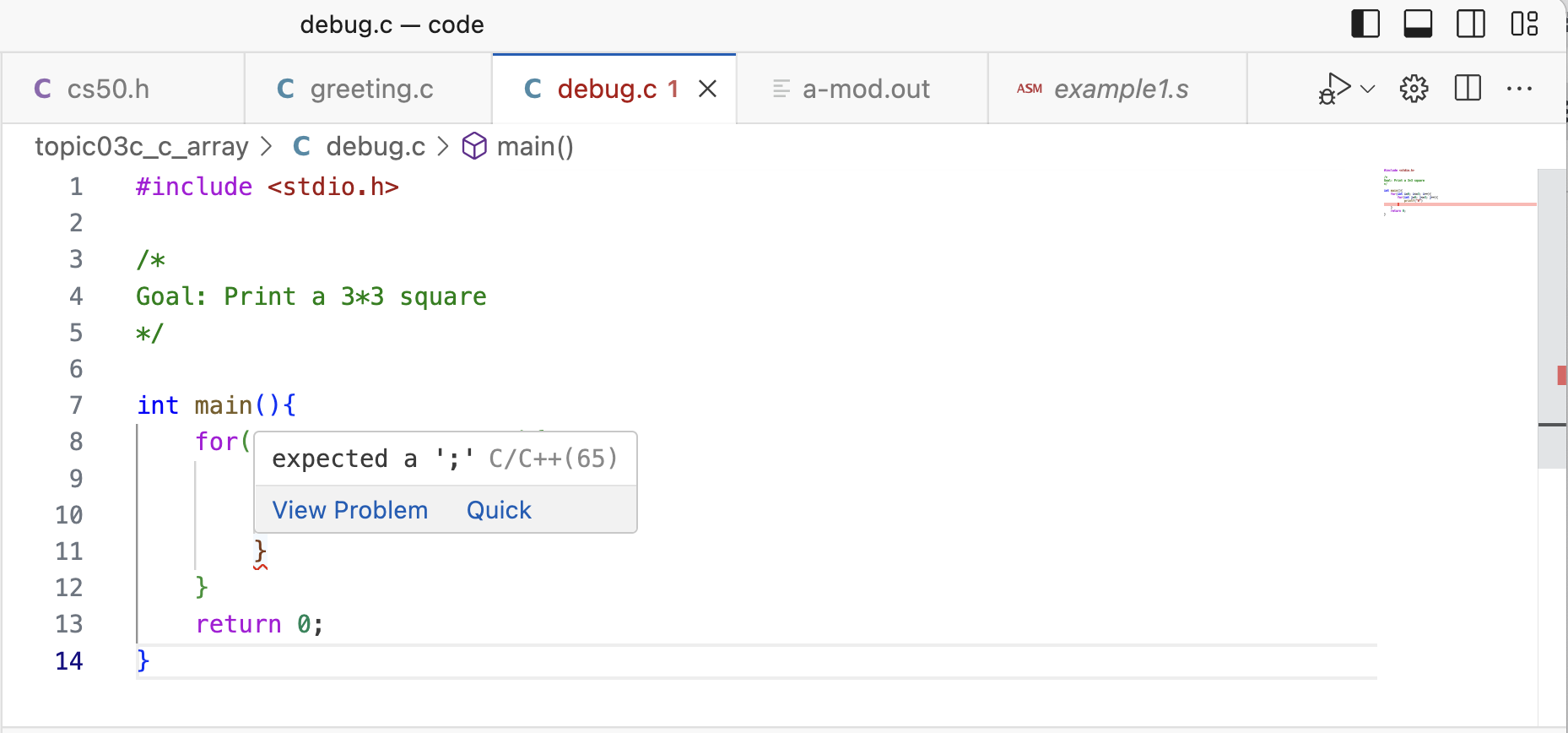
嗯, 这样子你就需要在后面加上一个分号了. 因为这个是我们C里面的规定.
然后是运行
过了编译器, 接下来就是运行时看看是不是符合我们的预期了. 如果在运行的时候, 我们发现没有满足我们的预期, 那么就可以使用调试器. 让它帮助我们理解它是如何进行执行的.
调试的思考
在调试的时候, 我们实际上是反复地在脑子(或者工具中)考察这样子的状态:
- 现在程序执行到哪一行了?
- 现在机器里面的状态是什么?
这里的状态, 实际上包含的是现在在执行哪一个函数? 以及现在变量的值都是多少.
根据我们以前的知识, 变量是存在内存里面的. 那么, 内存长什么样?
实际上, 内存里面所有的内容都仅仅有两个 "状态" -- 即 $0$ 和 $1$ . 一般而言, 计算机会给一些类型分配固定的长度. 比如, 在某一个版本的 C 中, int 会占用 32 位. 这就表示了 int 的最大值是 2147483647 -- 因为有一位需要表示符号, 我们只能有 $2^{31}$ 个可以用的位数.
一般而言, int, float会占用 32 位; 而更高精度的类型如 long, double 会占用 64 个位. 有些简单的类型如 char 只会占用 8 位. 在现代的机器上面, 类型大小大部分是 8 位的一个整数. 所以我们习惯上面称 8 位为一个字节. 当然, 这个单位可能只是一种大致的说法, 我们在这里没有给它下一个准确的定义.
但是这件事情好像对于我们以前的一个内容不是很奏效: 那就是string. 想一想, 如果输入了 10 个字母, 和输入了 100 个字母, 内存的占用肯定是不一样的. 实际上, string 是和刚刚的那一类变量不大一样的. 因为本质上, string 就是许多个 char 连成一串得到的结果. 我们能不能让电脑一次给我们分配多个内存空间呢?
这样是可以的. 这就是数组的观念. 比如我们希望创建一组 64 个int, 我们都可以这样声明变量:
int x[64];
在后面加上一个[], 在中括号里面写一个常数代表大小, 就可以让计算机帮助我们分配那么多个的变量了.
ASIDE: 数组长度为变量会怎么样? 实际上会有很多麻烦的事情. 在一些新的标准下, 这样的模式已经被弃用.
那么我们应该如何拿到, 修改这些变量呢? 比如我们想让x的第1个元素赋值为100, 应该怎么办? 我们可以这样写:
x[0] = 100;
由于计算机的内存是从 0 开始计数的(为了让计算机在操作内存单元的时候方便些), 所以普通话里面的 "第几个" 就变成了这里面的 "第几减一个".
这时候, x[0] 在等号的左边(有时候专业一点会叫做"左值"), 那么 C 就会找到 x[0] 的空间, 然后把 100 写进这个单元里面. 这样你在一个数学表达式中去要索取x[0]的时候, C就会去找到那个地方, 然后把内存的值取出来.
为了确保我们大概理解了这些内容, 我们决定来看几个有趣的练习.
例子1. 处理物理实验中的数据. 在高中物理实验中, 我们感到比较折磨. 因为就那几个数据在计算的时候非常的麻烦! 这样重复, 具有机械的属性的计算显然是让人类很不快的. 因此, 我们可以输出$n$个数的平均值 -- 这个功能基本是任何实验都要有的一个步骤.
例子2. 凯撒密码. 你要做的是平移字母到下一个单位, 得到最后的密码.
$$ -\mathscr {E}\text{nd of the note}- $$